DataFusion 0.2.1 Benchmark
March 17, 2018
Latest Benchmarks
This blog post is from more than four years ago. For latest information on DataFusion and Ballista benchmarks, see https://github.com/datafusion-contrib/benchmark-automation
Original Post
Over the past week or so I have been refactoring the core of DataFusion to convert it from a row-based execution engine to perform column-based processing. This was a pretty large refactoring effort but I am now back to roughly the same level of functionality as before (which is definitely still POC but capable of running some real queries).
Data is now processed in batches of columns instead of one row at a time. Each column is represented as a vector of values using the ColumnData enum:
pub enum ColumnData {
BroadcastVariable(Value),
Boolean(Vec<bool>),
Float(Vec<f32>),
Double(Vec<f64>),
Int(Vec<i32>),
UnsignedInt(Vec<u32>),
Long(Vec<i64>),
UnsignedLong(Vec<u64>),
String(Vec<String>),
ComplexValue(Vec<Rc<ColumnData>>)
}
The advantage of column based processing is that many operations can now take advantage of vectorized processing and hopefully Rust can generate SIMD instructions in many cases. I have yet to confirm if and when this is happening but I have been running a simple benchmark against both DataFusion and Spark and results are looking very promising.
I’m planning on adopting Apache Arrow as the native memory model for DataFusion and this refactor gets me a little closer to that goal.
Use Case
This first benchmark is very loosely based on a real-world use case where a list of locations need to be translated into a “well-known text” (WKT) format for processing by geospatial services.
This is a simple SQL statement that involves a projection, a table scan, a couple of UDFs and one simple UDT. For this benchmark both the input and output files are in CSV format.
SELECT ST_AsText(ST_Point(lat, lng)) FROM locations
I generated some random input files of varying size from 10 rows (10^1) to 1 billion rows (10^9). I had to stop there for now because I ran out of disk space on my 120GB SSD drive.
These initial test are single-threaded and not partitioned because DataFusion doesn’t support distributed and partitioned workloads yet.
Disclaimers
Benchmarks are hard. It takes tons of effort to make benchmarks that are truly fair comparisons of two systems with different fundamental design choices. Some use cases will perform better on one system and others will perform worse. I am aware that this first benchmark is a pretty trival use case. I also haven’t attempted to tune the Apache Spark configuration.
With that out of the way …
Results
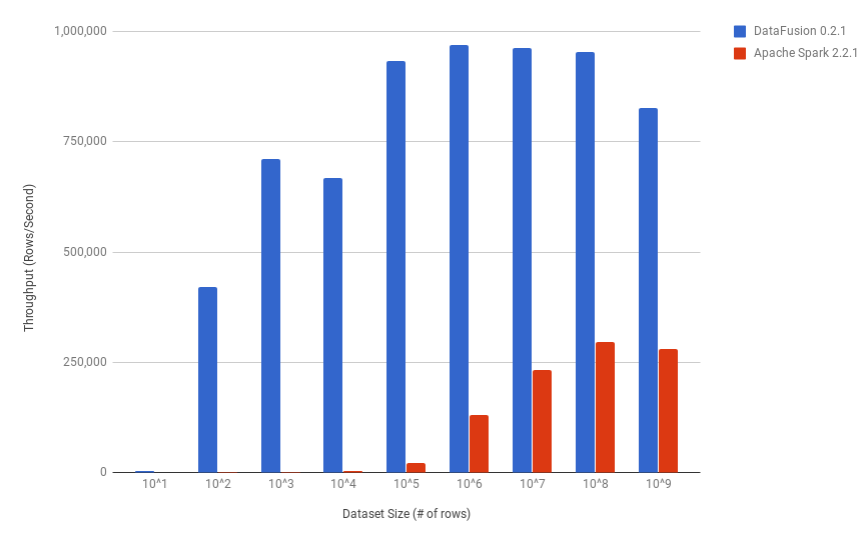
This chart shows throughput (rows/second) for processing input files of varying sizes from 10 rows to 1 billion rows. The tests ran on a deskop with 16GB RAM and the largest input file was ~48GB.
Summary
As expected, DataFusion outperforms Spark by many orders of magnitude on tiny datasets because Spark is optimized for large datasets and has an upfront cost due to the code generation stage. Although DataFusion does have upfront cost too in terms of compiling the query plan to Rust closures, it is a very lightweight operation in comparison.
I monitored CPU usage during the test runs and observed that DataFusion kept one core at 100% very consistently until it became I/O bound and was waiting on the SSD, whereas Spark has bursts of individual cores being at 100% and then switches to another core with some gaps between where the CPU is not being fully utilized.
I also observed that the Spark process used orders of magnitude more memory than DataFusion as would be expected due to the way Java allocates heap memory.
DataFusion was limited by the speed of my SSD drive and peaked at around 950,000 rows per second, which seems pretty good for a single core.
I’m not sure exactly what is limiting Spark but it peaked at around 300,000 rows per second for the larger datasets.
Reproducing the Benchmark
The source code for the benchmarks can be found at https://github.com/ballista-compute/benchmarks and these results are from commit id b660edd637004641437f702bc30a4d9db807e92b.
I would be interested to hear what performance characteristics others see.
Next Steps
In terms of benchmarking, I think I need to invest in a larger SSD for local testing and it is probably time to start setting up some automated benchmarks on EC2.
In terms of functionality, the next areas of focus are:
- Supporting Apache Arrow as the native memory model.
- Implementing columnar storage (a simple native format for now, but eventually supporting Parquet).
- Implementing partitioning and streaming of data between worker nodes, so that distributed jobs can be executed
- Implement SORT and JOIN operations so that more realistic workloads can be executed
Come join the fun!
I’m still the main contributor on this project although I am very happy to have had some smaller contributions from several other developers. I’ve been burning quite a few weekends lately to get to this point and luckily I have a very supportive wife but I’ll probably be slowing down the pace a little now. This is a fun research project but I would love to see it becoming useful to others over time. If you are interested in contributing, come join the gitter channel and chat with me!