DataFusion 0.13.0 Benchmarks
April 28, 2019
Latest Benchmarks
This blog post is from more than three years ago. For latest information on DataFusion and Ballista benchmarks, see https://github.com/datafusion-contrib/benchmark-automation
Original Post
Over the past couple weeks I’ve been working on a couple different efforts around parallel query execution with DataFusion:
- Benchmarking parallel query execution by manually creating one execution context per parquet partition and running on a thread, just to get an idea of expected performance, and comparing results to Apache Spark (running in local mode).
- Creating a PoC of actual parallel query execution in the Arrow/DataFusion repository.
This post is mostly about the first effort. I have created benchmarking code for Apache Spark and DataFusion (part of Apache Arrow) in the datafusion-benchmarks repository. The benchmarks are not 100% fair but close enough for now. In both cases, aggregate queries are running in parallel across 96 parquet files. The DataFusion benchmark doesn’t yet aggregate the results from all of those aggregates, but it’s only ~1000 rows so I wouldn’t expect that final aggregate phase to have much impact on these numbers.
The benchmarks are running simple aggregate queries against the NYC Taxi and Limousine Commission Public Dataset which has over 1 billion rows. I converted the files from CSV to Parquet using Spark (source code is in the benchmark repo).
I am running these tests on “ripper”, which is my home desktop with 24 cores (see hardware for detailed specs). Rust nightly version was rustc 1.34.1 (fc50f328b 2019-04-24). Apache Spark version was 2.4.1.
Aggregate 1
Query: SELECT MIN(tip_amount), MAX(tip_amount) FROM tripdata
Apache Spark Results
./gradlew run --args='bench /home/andy/nyc-tripdata/parquet "SELECT MIN(tip_amount), MAX(tip_amount) FROM tripdata" 5'
Iteration 1 took 3.799 seconds
Iteration 2 took 1.236 seconds
Iteration 3 took 1.171 seconds
Iteration 4 took 1.062 seconds
Iteration 5 took 1.05 seconds
Apache Arrow (DataFusion) Results
cargo run --release -- bench --path /home/andy/nyc-tripdata/parquet --sql "SELECT MIN(tip_amount), MAX(tip_amount) FROM tripdata" --iterations 5
Iteration 1 took 1.063737847 seconds
Iteration 2 took 0.933437641 seconds
Iteration 3 took 0.888571339 seconds
Iteration 4 took 0.869718541 seconds
Iteration 5 took 0.892783419 seconds
Notes
DataFusion is more than 3x faster than Spark for a one-off query. I expect this is due to the JVM warmup costs as the JIT compiler kicks in. On subsequent runs, DataFusion is marginally faster than Spark.
Aggregate 2
Query: SELECT passenger_count, MIN(fare_amount), MAX(fare_amount) FROM tripdata GROUP BY passenger_count
Apache Spark Results
./gradlew run --args='bench /home/andy/nyc-tripdata/parquet "SELECT passenger_count, MIN(fare_amount), MAX(fare_amount) FROM tripdata GROUP BY passenger_count" 5'
Iteration 1 took 6.695 seconds
Iteration 2 took 2.899 seconds
Iteration 3 took 2.95 seconds
Iteration 4 took 2.834 seconds
Iteration 5 took 3.588 seconds
Apache Arrow (DataFusion) Results
cargo run --release -- bench --path /home/andy/nyc-tripdata/parquet --sql "SELECT passenger_count, MIN(fare_amount), MAX(fare_amount) FROM tripdata GROUP BY passenger_count" --iterations 5
Iteration 1 took 6.44939232 seconds
Iteration 2 took 6.486942068 seconds
Iteration 3 took 6.716076313 seconds
Iteration 4 took 6.665406168 seconds
Iteration 5 took 6.305032992 seconds
Notes
DataFusion doesn’t perform so well with GROUP BY. I think this is due to the current implementation being essentially row-based and using pattern matching and array downcasts on every value being aggregated in every row. I have an idea for an improved design that would better leverage the columnar data model. I plan on trying that out once DataFusion supports parallel query execution for real. You can follow my progress in this pull request.
Memory Usage
With the previous benchmarks, I left the JVM memory unconstrained and I noticed that Spark was using around 100x more memory than the DataFusion benchmark (8 GB compared to 80 MB!) so I ran the benchmarks again but this time constraining the JVM to a fixed size heap between 1 and 8 GB (1 GB seems to be the realistic minimum memory footprint for Spark).
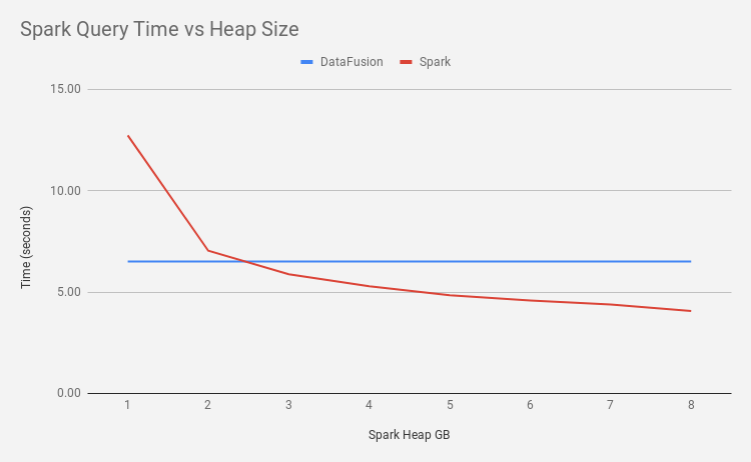
These results are interesting. DataFusion is twice as fast as Spark when Spark is constrained to 1 GB. Spark actually needed 3 GB of RAM to be able to outperform DataFusion. That’s 37.5 x more memory than DataFusion needed (3 GB vs 0.08 GB).
These results are pretty encouraging for DataFusion having much lower TCO than Spark and for DataFusion being easier to scale vertically on a single instance, removing the overhead of a distributed cluster for some use cases.