How To Build A Modern Distributed Compute Platform
November 1, 2018
February 2020 Update: I have now written a book How Query Engines Work based on the content in this article.
Introduction
I have been involved in several projects over the past decade where I have built query engines and distributed databases, the latest being my open source Ballista project. The sophistication of these projects has varied wildly and I have learned plenty of lessons the hard way. That said, this has been, and will continue to be, an exciting journey for me.
This article is an attempt to write a fairly comprehensive guide on all aspects of building a distributed compute platform and discuss some of the design choices and trade offs that must be made along the way. I am hoping this also serves as a guide to document the design choices I have made for Ballista and will make it easier for others to contribute.
This is a work in progress that I will be fleshing out over time.
Big Picture
The reason that we have distributed compute platforms is that it often isn’t feasible to process large data sets on a single computer because:
- Memory constraints: We often can’t load all of the data into memory on a single node, resulting in expensive disk I/O.
- CPU constraints: There are only so many CPU cores available on a single node, limiting concurrency and throughput.
- Disk constraints: Potentially, we can’t even fit the entire data set onto a single disk. Even if we can, each disk has finite throughput.
By running the computation in parallel across multiple nodes we can largely remove these resource constraints. For some computations, we will see linear scalability, so using 10 nodes instead of 1 node will mean that the job runs 10 times faster. For other computations this is not true because of the need to run a second phase of aggregration to combine the results from each node, or when we need to move data around between nodes for certain operations (re-partitioning, and SQL JOINs for example). This will be covered in more detail later.
At a high level, the architecture is actually very simple. We need a serializable representation of the computations we want to execute (usually referred to as a query plan or execution plan) so that we can distribute this plan, or subsets of it, to different nodes in a cluster and have each node execute the plan against a subset of the data.
One approach is to build a DAG (directed acyclic graph) of the tasks and then rely on an orchestration framework such as Kubernetes to run the tasks. Another approach is to build a cluster where nodes can dyamically connect to each other and send query plans and receive results. Results might be persisted to disk between tasks (as in MapReduce) or streamed between nodes (as in Spark or Flink), or some combination of both approaches.
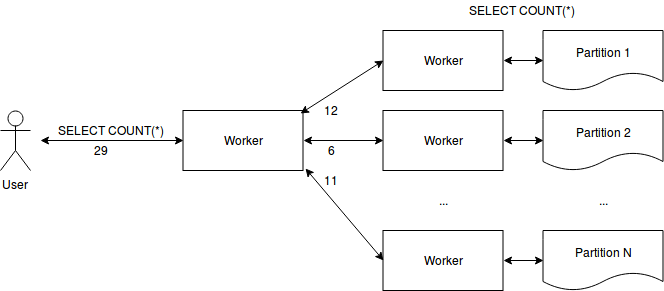
Diagram 1: One possible implementation of a distributed query to perform SELECT COUNT(*) on a partitioned data source. Each worker executes the query in parallel against a single partition and then the results are combined by another worker before the aggregate result is returned to the user issuing the query.
Type System and Memory Model
One of the first decisions to make is what type system to use. Our platform will deal with multiple data sources (such as CSV, Parquet, SQL databases, key-value stores, and so on) and potentially even interact with different programming languages, so there are multiple type systems that we need to support and map to one common type system.
Another decision is whether to use a row-based or column-based representation of the data. However, this isn’t really a decision any more. Row-based is simpler to implement but is incredibly inefficient. Using a columnar representation has many benefits, including:
- Efficient use of CPU cache when iterating over values within a column
- Columnar data can be efficiently compressed for improved disk and network throughput
- It is possible to use CPU support for SIMD (Same Instruction Multiple Data) to perform operations on multiple values within a column with a single CPU instruction rather than operating on one value at a time, leading to significant performance improvements in some cases
- Leverage GPUs for parallel compute on values within a column
Finally, we need to choose a memory model to represent the data.
I believe that Apache Arrow is the ideal choice for the memory model and type system because it is gaining wide support from the industry and there are many projects adding support for Arrow as a common memory model, to make it possible to share data between systems without the need to copy or serialize the data. There are already Arrow bindings in many languages too, including C, C++, Go, Java, JavaScript, Python, Ruby, and Rust.
Query Planners
We probably don’t want users to manually build a query plan, so the user will typically use a DataFrame style API to build the plan, or maybe just SQL. In either case, the user will want the flexibility to run custom code as part of the plan. This could be as simple as a scalar UDF or it could be more comprehensive code that operates on rows, columns, or even complete partitions of data.
For SQL we need the ability to parse the SQL into an AST (Abstract Syntax Tree) and then a query planner to generate the query plan from the AST in conjunction with additional information from a data source implementation (for example, we need meta data about the underlying data, such as column names and data types).
Query Optimizations
A naive implementation of a query execution engine that simply executes a query plan generated from SQL is unlikely to perform well. Consider the simple query SELECT id FROM customer WHERE state = 'CA' where the customer table has fifty columns. The logical query plan might look like this:
Projection: id
Selection: state = 'CA'
Table: customer
Executing this plan would likely load all fifty columns from disk, apply the filter, and then apply the projection to return the one column (id) that we care about.
An obvious optimization is to push the projection down to the data source so we only load the columns from disk that we actually need (which is incredibly efficient when using a columnar format).
The optimized plan would look something like this:
Projection: id
Selection: state = 'CA'
Table: customer; columns = [id, state]
Note that both the id and state columns need to be loaded since they are both referenced in the plan. This simple optimization has potentially resulted in a 25x boost in performance (becase we are reading two columns from disk instead of fifty).
A mature query optimizer will contain dozens of optimization rules. Usually one rule is applied at a time in a specific order, with each optimizer rule transforming an input plan to an output plan.
For more information, see the wikipedia article on query optimization.
Cost-based Optimizations
Cost-based optimizations are a very specific category of optimizations that adjust the query plan based on statistics about the tables being queried. These statistics can be as simple as the number of rows and columns, but can also be more detailed and include information on I/O costs. An example of a cost based operation is swapping the left and right inputs to a hash join so that the smaller table is on the left (assuming the left one is loaded into memory).
It should largely be possible to determine the cost of execution a query based on the optimized plan and knowledge of the performance characteristics of the execution environment.
Logical vs Physical Plan
The logical plan deals with logical operations such as Join and Aggregate whereas the physical plan deals with specific implementations such as InnerLoopJoin, MergeJoin, and HashAggregate. The physical plan is generated from the logical plan.
Supporting Custom Code
A DataFrame/SQL approach handles quite a lot but at some point users need to add custom logic as part of the query or job. I don’t think it is a good idea to make this specific to a single implementation language. Apache Spark is very much a JVM-first solution and that makes it difficult when using other languages.
In an ideal world, it should be possible to support custom code in multiple languages. Here are some ways of achieving this:
- Compile custom code to some intermediate format (I am hopeful that WebAssembly might be a good choice)
- Compile custom code to dynamically linked libraries and include them in the docker image deployed to the cluster (good for systems level languages, not so good for JVM and others)
Query Execution
One approach to query execution is to recursively walk through the query plan and map each relation in the plan to code that performs the necessary action to create the relation. This approach is simple but the downside is that it leads to overhead of dynamically evaluating expressions.
A more efficient approach is to generate code from the query plan and then compile that code. The generated code would typically be Java byte code, or LLVM, but could theoretically be any compiled language.
Query Execution Deep Dive
Let’s talk in more detail about some of the specific operations that we need to perform.
Sorting Data
We can sort data in parallel to produce a sorted set of data per partition. We can then use a merge algorithm to combine these sets while maintaining sort order.
Aggregating Data
To aggregate data by a set of grouping expressions we employ slightly different algorithms depending on whether the input data is sorted by the grouping expressions or not.
If the input data is unsorted, we either sort it first, or we need to maintain a data structure where we have one aggregate row for each unique set of grouping expressions. Depending on the cardinality of the grouping expressions, the number of aggregate rows we need to maintain during the operation could be as low as one or as high as the row count of the input data source. This type of aggregate is commonly known as HashAggregate. If the input data is already sorted by the grouping expression than the input rows can be combined more efficiently without having to maintain a large hash map. This type of aggregate is known as a GroupAggregate.
The aggregate row consists of zero or more values for the grouping expressions and then one or more accumulators for the aggregate expressions. Accumulators for COUNT, MIN, MAX, SUM are simple scalar values. Accumulators for COUNT(DISTINCT) need to maintain a set of all unique values encountered and therefore can be very expensive. If the COUNT(DISTINCT) is being performed on an integer value then a bitmap index can be used for memory efficiency.
If the input data is already sorted by the grouping expressions then only one aggregate row needs to be maintained in memory at any time and can be streamed to the caller (or wriiten to disk) once all rows have been processed for the current grouping values.
Joins
Distributed joins are often expensive because of the need to re-partition data and then stream data between nodes. This becomes an exponential cost as the number of partitions increases. Joins can be efficient if both sides of the join are already partitioned on the join keys and if the data is co-located such that each node can simply perform a join between local files.
There are many different join algorithms to choose from but the two that are most often used seem to be sort-merge join and hash join.
Distributed Data Challenges
TBD, will talk about
- Move data to compute vs move compute to data
- Data locality and caching vs remote data (HDFS/S3)
- Shuffles
- Repartioning
- Moving data
- Serialization formats and overheads
- Batch vs streaming, and how JOIN impacts that
Optimizations
What are we optimizing for?
- Single Node vs Distributed
- CPU vs GPU
- Disk (SSD / NVMe) vs Memory (DRAM, Optane)
- Network (Gigabit, 10g)
Non Functional Concerns
Programming Languages
I’m a huge fan of languages that use garbage collectors, in general, but for something like this I have a very strong bias towards systems level languages at least for the query execution code.
However, for end users constructing queries, there should be bindings for multiple popular languages, such as Python and Java at a minimum. Generally speaking, end users are just building query plans, maybe with some custom code thrown in. One of the advantages of using Apache Arrow as the memory model is that we can support multiple languages in query execution without paying the cost of copying/serializing data using an IPC mechanism.
Security
Security largely seems to be overlooked in many distributed compute platforms today (with the exception perhaps of managed services from the major cloud providers). At a minimum, I believe the following features should be designed in from day one:
- Authentication
- Authorization
- Encryption at rest (data files should be encrypted)
- Encryption in transit (SSL/TLS between nodes)
I have seen a number of research papers on advanced topics such as being able to perform computations on encrypted data without ever decrypting the data. This can be acheived using homomorphic encryption for example. This isn’t an area that I am particularly interested in and seems like a world of pain.
Configuration
One of my pet peeves with Apache Spark is that configuration is often hard-coded into applications. Spark doesn’t particularly force this to happen but it’s just easy to fall into this approach. When a job that has been running perfectly fine for months starts crashing with out of memory exceptions than developers randomly change some config values in code and release a new version. This all seems very brittle.
Ideally we should be able to control all configuration externally to code, and ideally in real time too.
Monitoring and Debugging
Distributed systems are hard to comprehend and hard to debug. It is essential to build in good logging and metrics early on and make the information easy to access and navigate so that it is possible to debug issues.
High Availability / Resiliency
TBD
Conclusions
As you can see, there are a huge number of factors to consider and a lot of code to implement in order to build a distributed compute platform.
Building distributed systems can be fun! However, there are already a huge number of open source Big Data projects that aim to provide a solution. There are pros and cons to each one for sure, but building your own distributed compute platform is a major undertaking.
I have chosen to build Ballista for some good reasons though (IMHO):
- I want to learn as much as possible about this domain, and there’s no better way to get a deep understanding than attempting to build it yourself
- I wanted a real project in order to learn more about the Rust programming language
- I wanted to inspire others to build useful things in Rust that can help drive the adoption of Rust for distributed compute (see my Rust is for Big Data blog post for more detail)
Glossary
- Cardinality - The number of items in a set
- Projection - Selecting a subset of columns from a relation
- Relation - A set of tuples (this could be a table or the result of applying an operation to a table)
- Selection - Selecting a subet of rows based on a filter expression e.g. a WHERE clause